difference between random forest and xgboost, check these out | Which is better random forest or XGBoost?
One of the most important differences between XG Boost and Random forest is that the XGBoost always gives more importance to functional space when reducing the cost of a model while Random Forest tries to give more preferences to hyperparameters to optimize the model.
Which is better random forest or XGBoost?
If the dataset has no many differentiations and we are new to decision tree algorithms, it is better to use Random Forest as it provides a visualized form of the data as well. If we want to explore more about decision trees and gradients, XGBoost is good option.
Is XGBoost random forest?
The XGBoost library provides two wrapper classes that allow the random forest implementation provided by the library to be used with the scikit-learn machine learning library. They are the XGBRFClassifier and XGBRFRegressor classes for classification and regression respectively.
What is the difference between random forest and boosting?
Bagging vs Boosting
The main difference between random forest and GBDT is how they combine decision trees. Random forest is built using a method called bagging in which each decision tree is used as a parallel estimator. GBDT uses boosting technique to create an ensemble learner.
Why XGBoost is faster than random forest?
Xgboost does capture non linear relationships. It has performed well on many tabular datasets with a fair amount of data. It produces smaller trees compared to RandomForest and can fit data better than a single on boosted tree. By use of gradient boosting it can optimize arbitrary metrics.
Is XGBoost a decision tree?
XGBoost, which stands for Extreme Gradient Boosting, is a scalable, distributed gradient-boosted decision tree (GBDT) machine learning library.
Is random forest supervised or unsupervised?
Random forest is a Supervised Machine Learning Algorithm that is used widely in Classification and Regression problems.
What is better than a random forest?
If you carefully tune parameters, gradient boosting can result in better performance than random forests. However, gradient boosting may not be a good choice if you have a lot of noise, as it can result in overfitting. They also tend to be harder to tune than random forests.
Where can I use random forest XGBoost?
These algorithms give high accuracy at fast speed. Both the two algorithms Random Forest and XGboost are majorly used in Kaggle competition to achieve higher accuracy that simple to use.
What is difference between decision tree and random forest?
A decision tree combines some decisions, whereas a random forest combines several decision trees. Thus, it is a long process, yet slow. Whereas, a decision tree is fast and operates easily on large data sets, especially the linear one. The random forest model needs rigorous training.
Why do we use XGBoost?
You learned: That XGBoost is a library for developing fast and high performance gradient boosting tree models. That XGBoost is achieving the best performance on a range of difficult machine learning tasks. That you can use this library from the command line, Python and R and how to get started.
How is XGBoost different from gradient boosting?
XGBoost is a more regularized form of Gradient Boosting. XGBoost uses advanced regularization (L1 & L2), which improves model generalization capabilities. XGBoost delivers high performance as compared to Gradient Boosting. Its training is very fast and can be parallelized across clusters.
What is the difference between GBM and XGBoost?
There has been only a slight increase in accuracy and auc score by applying Light GBM over XGBOOST but there is a significant difference in the execution time for the training procedure. Light GBM is almost 7 times faster than XGBOOST and is a much better approach when dealing with large datasets.
Is random forest slower than XGBoost?
For most reasonable cases, xgboost will be significantly slower than a properly parallelized random forest. If you’re new to machine learning, I would suggest understanding the basics of decision trees before you try to start understanding boosting or bagging.
What is random forest method?
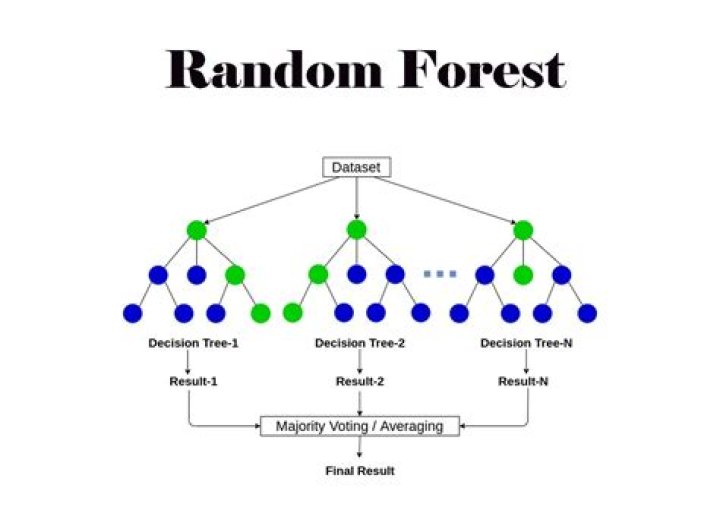
Random forests or random decision forests are an ensemble learning method for classification, regression and other tasks that operates by constructing a multitude of decision trees at training time. For regression tasks, the mean or average prediction of the individual trees is returned.
What is random forest How does it work?
The random forest is a classification algorithm consisting of many decisions trees. It uses bagging and feature randomness when building each individual tree to try to create an uncorrelated forest of trees whose prediction by committee is more accurate than that of any individual tree.
How do you explain XGBoost?
What is XGBoost? XGBoost is a decision-tree-based ensemble Machine Learning algorithm that uses a gradient boosting framework. In prediction problems involving unstructured data (images, text, etc.) artificial neural networks tend to outperform all other algorithms or frameworks.
Related Archive

harry potter wizards unite wand guide, latest free online harry potter movies, best HD videos you should watch in 2022 – 2023

harry potter villain test, latest free online harry potter movies, best HD videos you should watch in 2022 – 2023

harry potter uk edition books, latest free online harry potter movies, best HD videos you should watch in 2022 – 2023

