lda number of topics, check these out | What is the optimal number of topics for LDA in Python?
The above LDA model is built with 10 different topics where each topic is a combination of keywords and each keyword contributes a certain weightage to the topic.
What is the optimal number of topics for LDA in Python?
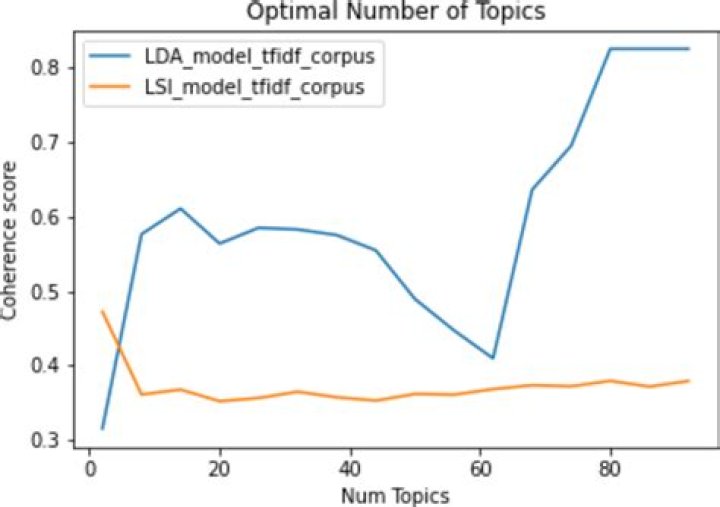
A general rule of thumb is to create LDA models across different topic numbers, and then check the Jaccard similarity and coherence for each. Coherence in this case measures a single topic by the degree of semantic similarity between high scoring words in the topic (do these words co-occur across the text corpus).
How many topics should a topic model have?
The RPC-based method (green bars) chose 20 topics as most appropriate for 80% of the models, and 10, 30 or 40 topics for the remaining 20%.
How do you find the number of topics?
One way to determine the number of topics is to consider each topic as a cluster and then to evaluate the effectiveness of such clusters using known metrics such as Silhouette (clustering) – Wikipedia .
How many parameters does LDA have?
Hence, the total number of estimated parameters for LDA is (K-1)(p+1). Similarly, for QDA, we need to estimate (K-1){p(p+3)/2+1} parameters. Therefore, the number of parameters estimated in LDA increases linearly with p while that of QDA increases quadratically with p.
What is the best number of topics for LDA?
To decide on a suitable number of topics, you can compare the goodness-of-fit of LDA models fit with varying numbers of topics. You can evaluate the goodness-of-fit of an LDA model by calculating the perplexity of a held-out set of documents. The perplexity indicates how well the model describes a set of documents.
What is a good coherence score for LDA?
Contexts in source publication
achieve the highest coherence score = 0.4495 when the number of topics is 2 for LSA, for NMF the highest coherence value is 0.6433 for K = 4, and for LDA we also get number of topics is 4 with the highest coherence score which is 0.3871 (see Fig.
How do you evaluate LDA models?
LDA is typically evaluated by either measuring perfor- mance on some secondary task, such as document clas- sification or information retrieval, or by estimating the probability of unseen held-out documents given some training documents.
What is corpus in LDA?
A corpus is simply a set of documents. You’ll often read “training corpus” in literature and documentation, including the Spark Mllib, to indicate the set of documents used to train a model.
What is LDA topic modeling?
Latent Dirichlet Allocation (LDA) is a popular topic modeling technique to extract topics from a given corpus. The term latent conveys something that exists but is not yet developed. In other words, latent means hidden or concealed. Now, the topics that we want to extract from the data are also “hidden topics”.
How do you evaluate a topic model?
There are a number of ways to evaluate topic models, including:
Human judgment. Observation-based, eg. observing the top ‘N’ words in a topic. Quantitative metrics – Perplexity (held out likelihood) and coherence calculations.Mixed approaches – Combinations of judgment-based and quantitative approaches.
How do I choose LDA parameters?
The most important tuning parameter for LDA models is n_components (number of topics). In addition, I am going to search learning_decay (which controls the learning rate) as well. Besides these, other possible search params could be learning_offset (downweigh early iterations. Should be > 1) and max_iter .
What is perplexity LDA?
Perplexity is a statistical measure of how well a probability model predicts a sample. As applied to LDA, for a given value of , you estimate the LDA model. Then given the theoretical word distributions represented by the topics, compare that to the actual topic mixtures, or distribution of words in your documents.
Is Latent Dirichlet Allocation clustering?
Strictly speaking, Latent Dirichlet Allocation (LDA) is not a clustering algorithm. This is because clustering algorithms produce one grouping per item being clustered, whereas LDA produces a distribution of groupings over the items being clustered.
How does LDA reduce dimensionality?
Linear Discriminant Analysis also works as a dimensionality reduction algorithm, it means that it reduces the number of dimension from original to C — 1 number of features where C is the number of classes. In this example, we have 3 classes and 18 features, LDA will reduce from 18 features to only 2 features.
What is discriminant score in LDA?
Linear discriminant analysis (LDA), normal discriminant analysis (NDA), or discriminant function analysis is a generalization of Fisher’s linear discriminant, a method used in statistics and other fields, to find a linear combination of features that characterizes or separates two or more classes of objects or events.
How do I choose K for LDA?
Method 1: Try out different values of k, select the one that has the largest likelihood. Method 3: If the HDP-LDA is infeasible on your corpus (because of corpus size), then take a uniform sample of your corpus and run HDP-LDA on that, take the value of k as given by HDP-LDA.
What is topic modeling used for?
Topic Models are very useful for the purpose for document clustering, organizing large blocks of textual data, information retrieval from unstructured text and feature selection. For Example – New York Times are using topic models to boost their user – article recommendation engines.
How do you increase your coherence score?
Usually, the coherence score will increase with the increase in the number of topics. This increase will become smaller as the number of topics gets higher. The trade-off between the number of topics and coherence score can be achieved using the so-called elbow technique.
Related Archive

harry potter wizards unite apple, latest free online harry potter movies, best HD videos you should watch in 2022 – 2023

harry potter uniform shop, latest free online harry potter movies, best HD videos you should watch in 2022 – 2023

harry potter wand name list, latest free online harry potter movies, best HD videos you should watch in 2022 – 2023

